Exploring the difficulties of soundtracking with AI
Evaluating soundtracking models, and why existing metrics only partially capture perceived quality.

Selecting the right sound effects and music for a video — what Epidemic Sound calls soundtracking — is a deceptively difficult problem for AI. A good soundtrack must be semantically appropriate, temporally aligned, and creatively coherent, yet there is rarely a single “correct” answer. Two different sound designs for the same video can both feel right.
Epidemic Sound is exploring this problem through Studio: an AI-powered workflow that recommends sound effects and music for video. Given a clip, Studio suggests a complete audio layer, from foreground effects to transitions and background music.
Soundtracking overlaps with foley — the practice of recreating on-screen sounds in post-production — but goes beyond it. In addition to diegetic sounds like footsteps or doors, Studio also recommends non-diegetic elements such as music and transitional effects. In other words, it’s not just reproducing reality; it’s helping shape the emotional and narrative arc of a video.
From a machine learning perspective, soundtracking is an open-ended, multimodal generation and retrieval task. Models may use visual frames, existing audio, and text metadata, but evaluating their output is fundamentally challenging: there is no ground truth soundtrack.
This raises a key question: how do you evaluate soundtracking models at all?
How to evaluate soundtracking models
Soundtracking as a task is not something that has been much explored in the machine learning literature, but a closely related topic is training models for producing foley sounds for a given video. It is worth mentioning that some systems, such as MMAudio[3], can generate music as well, due to music being present in the training data.
Predicting foley sounds is slightly less subjective in nature, and for this task, we most often want to predict the sound of some object or event in the video. We expect the audio to be both semantically and temporally aligned with the video.
- Semantic alignment means that what you see and hear fits well together. For example, if you see a dog barking, you would preferably like to hear a dog barking as well.
- Temporal alignment means that the timing of the audio events match the video. For example, if you see someone kicking a ball, the sound of the kick matches when the foot hits the ball.
There are two common ways of measuring these dimensions. ImageBind[1] scores (IB score) are used for measuring semantic similarity between audio and video, and Synchformer[2] synchronization score measures whether the audio matches the video in time. Let’s take a look at each measure and how they work.
ImageBind score
ImageBind is a model trained by Meta[1] that has learned a joint embedding space for six different modalities. These modalities are image/video, text, audio, depth data, thermal data, and inertial measurement unit (IMU) data.
Multimodal datasets with six modalities are extremely scarce, and for these specific modalities most likely non-existent. So, to solve the data shortage, Meta trained its model on datasets of pairwise modalities where one is always image or video.
For example, we have image-text and image-audio pairs in the data. By tying each modality to images, the model successfully learns a representation where we can compare and make queries for pairs of modalities not found in the training data, for instance querying audio using text.

Synchformer synchronization score
Synchformer[2] is a self-supervised transformer that predicts audio/video temporal misalignment. Given an audio stream and a video stream, the model itself predicts the time offset between the audio and video.
The model is trained in two parts. First, the feature extractors for the audio and images are trained separately. They are later frozen and a synchronization module is trained. The synchronization module outputs the offset, which can be used to both gauge temporal offset as well as to synchronize audio to video.
This results in a model that has become state of the art for several synchronization tasks.
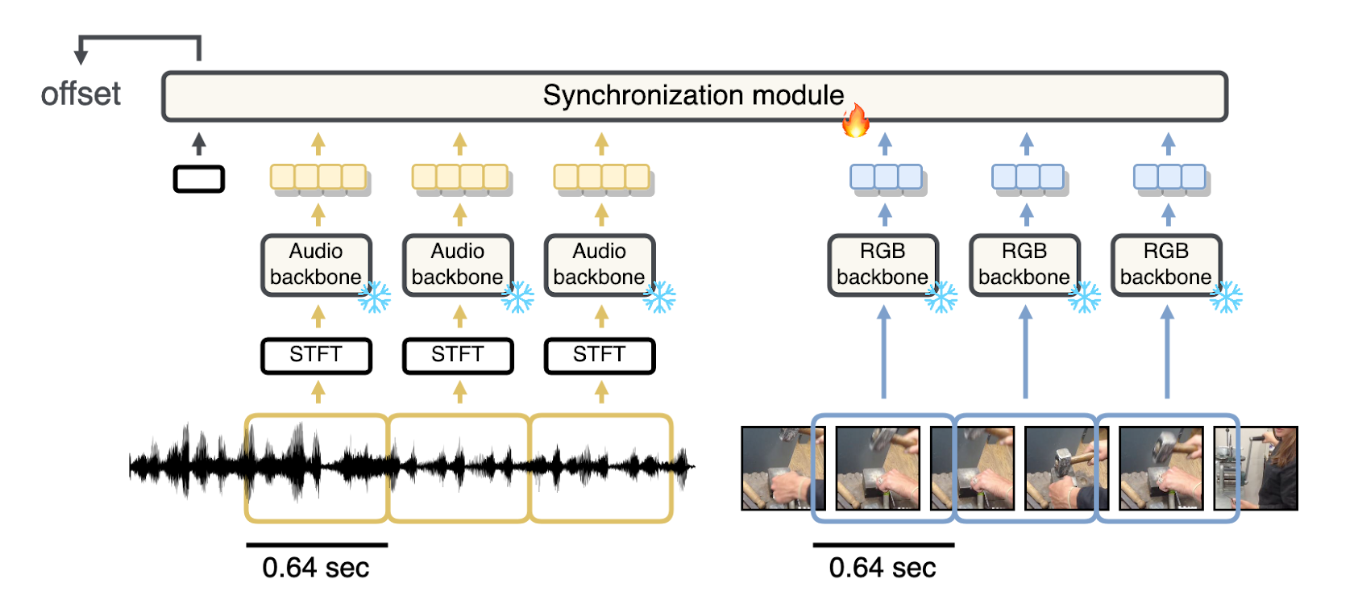
Evaluating soundtracking models with ImageBind and Synchformer
To put these metrics to the test, we decided to compare a couple of generative soundtracking systems, including baselines we conceived for this evaluation. We compared a mix of open-source, internal, and commercial soundtracking systems in addition to two baselines. One of the baselines predicts silence for every video, while the other one randomly swaps audio between videos.
To compare these systems, we used videos from a few public and internal datasets and let each system predict the audio. We then measured IB scores using the public ImageBind checkpoint, and measured the average Synchformer top-1 predicted offsets using the Synchformer checkpoint trained on AudioSet.
Evaluating the evaluation
The results
On average, ranking according to the two scores matched our perception of quality. This means that the generative soundtracking systems received the best scores, with the baselines trailing behind.
The “random” soundtracker worked surprisingly well. If we consider the subjective nature of soundtracking, though, it is perhaps less surprising that sounds from one video can fit another one. In other words, it doesn’t sound that bad. Not according to our metrics, at least.
General shortcomings
As we have mentioned previously, soundtracking is a highly subjective task. This means that predictions might be missing elements from ground truth or be a completely different take on the soundtracking of a video, which could be considered just as correct.
However, there are some obvious shortcomings in today’s systems. Generally, we can see an absence of sounds that could be considered “obvious.” For example, background sounds – such as the steady, present hum of traffic – that you would expect if you see a video of a city might not be present in the audio.
The audio does not always sync with the video, either. Some systems also try to predict speech, which is for natural reasons a very difficult task. In this case, the systems should opt for silence, since Epidemic Sound users will most likely provide voice tracks.
Evaluation shortcomings
As mentioned, ranking the systems by the two metrics mostly correlated with our subjective perception. High scores for a soundtracking system correlated with it being perceived as better than a lower-ranked system on average.
However, we found plenty of cases where the scoring was not consistent and poor examples were rated better than ground truth. Here is a particularly egregious example, where the predicted audio was given a very high score — 0.300352 — and ground truth substantially lower, at 0.065939:
Ground truth (from VGGSound)
Random audio from another video
Poor kid! While this example might seem contrived, it clearly points to an example where IB score does not align with general sentiment of quality (of course, random sounds are always fun). We found plenty of cases like these.
A subtler difference can be found when comparing the two versions of the video below, with scores close to each other:
Ground truth (from Soundly)
Random audio from another video
Ground truth received 0.273007, and the random audio example received 0.313177. Ground truth got lower here as well, but not that much lower. As you might have gleaned from these examples, the right answer is not necessarily obvious.
Therein lies the challenge. The “random” example might not be the best match, but is it entirely wrong? If it is subjective and hard for us to tell, it will be even harder for any machine learning system, which we can tell from the scores where the scores are comparable.
We also observe that surprising sounds in the audio, which a viewer would most likely perceive as jarring and low-quality, does not particularly bother the IB score.
Despite these occasional shortcomings of the method, the score on average aligns with our perception. Generally, it seems that IB score can be used to filter out underperforming systems, but is not as useful for distinguishing between better-performing systems.
We also discovered that the Synchformer score behaved peculiarly. Part of the surprise was that for one of the datasets in our evaluation, most of the ground truth audios received non-perfect scores. This dataset consists of videos soundtracked by professionals, and can therefore be considered a gold standard. However, just like with the IB score, ranking by the Synchformer score correlates with our subjective perception of quality on average.
Best practice
These insights directly inform how Epidemic Sound built Studio. Rather than optimizing for any single metric such as ImageBind or Synchformer, automated evaluation is treated as one signal among many, alongside expert listening sessions and user feedback.
The goal is not merely to improve semantic similarity or synchronization scores, but to help creators tell better stories with sound — whether through subtle ambience, expressive transitions, or music that sets the right mood. At the same time, our findings mirror those in recent work such as MMAudio [3]: while current metrics are useful for coarse model comparison, they struggle to capture perceptual quality and creative coherence.
ImageBind and Synchformer remain widely used in the literature, largely because there are few strong alternatives, but their limitations highlight an important open research problem. Developing evaluation methods that better reflect human judgment — potentially by combining semantic, temporal, and perceptual signals — will be just as critical as improving generative models themselves.
Soundtracking sits at a unique intersection of machine learning and creativity. Bridging the gap between automated metrics and human experience remains an ongoing challenge, and one Epidemic Sound is actively exploring both through research and Studio.
References
[1] - ImageBind: One Embedding Space To Bind Them All. Girdhar, El-Nouby, Liu, Sing, Alwala, Joulin and Misra. CVPR 2023
[2] - Synchformer: Efficient Synchronization from Sparse Cues. Iashin, Xie, Rahtu and Zisserman. ICASSP 2024
[3] - MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis. Cheng, Ishii, Hayakawa, Shibuya, Schwing and Mitsufuji. CVPR 2025