When music generation models get mixed signals: Investigating conditioning conflicts in Adapt
As music generation models gain the ability to use multiple conditioning signals, such as text prompts and audio, a question arises: how do these signals interact, compound, or even compete? This post shares what we found.


Ideally, text prompts describe intent, while audio conditioning provides musical reference, enabling richer control and higher-quality outputs. In this post, we investigate how aligned versus conflicting text and audio conditioning signals affect prompt adherence in the generative model that powers Adapt.
What is Adapt?
Adapt is Epidemic Sound’s AI-powered music adaptation tool that helps creators shape tracks to better fit their content in a few clicks. Adapt uses Epidemic Sound’s proprietary latent diffusion model, which enables audio generation that follows a text prompt while musically matching a pre-selected track.
Clearly, this model is powerful and unlocks many use cases for users. For example, the model lets users tweak a track’s vibe to match a scene.
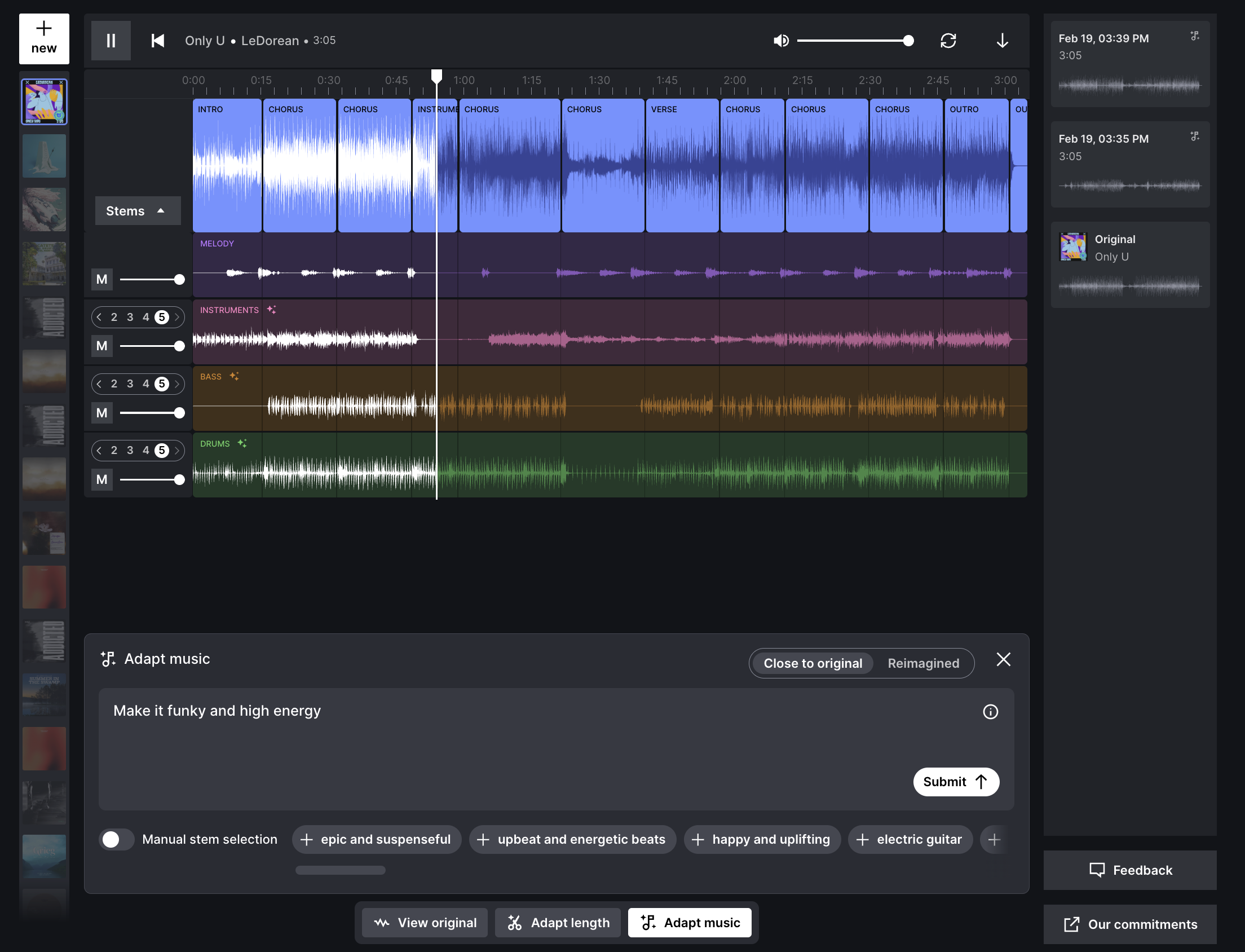
So, what’s special about Adapt?
Adapt leverages the model’s conditioning capabilities to modify tracks rather than create new ones. There are many commercial applications available that allow customers to generate music from text prompts. We call this type of audio generation text-to-music.
We are interested in another use case: allowing users to transform any track — where the artist has opted in to adaptation — from Epidemic Sound’s catalog of over 55,000 tracks by using a text prompt. We call this mode of generation stem-conditioned audio generation.
The model behind Adapt uses a method called rectified flows [1],[2]. Unlike iterative denoising diffusion models, the model learns a straight path from random noise to the music, conditioned on one or many conditioning signals $c$.
More formally: we define a straight line between the clean audio data ($x_0$) and random noise ($x_1$ = $\epsilon$, $\epsilon \sim \mathcal{N}(0, I)$). During the corruption process, we mix them using a time variable $t$, where $t=0$ is the music and $t=1$ is the noise:
$$x_t = (1-t)x_0 + t\epsilon$$
This creates a path where the velocity points directly from the music to the noise:
$$ v = \epsilon - x_0 $$
To generate music, we start with noise and move backward towards the audio data. We train a neural network $v_\theta$ to predict the velocity of the flow $v$. By solving the ordinary differential equation, we can learn to reverse the corruption process and generate audio samples:
$$ dx_t = -v_\theta(x_t, t, c)dt $$
The model is trained by minimizing the error between its predicted velocity ($v_\theta$) and the true velocity ($v$):
$$ \text{Loss} = \mathbb{E} \Big[ | v - v_\theta(x_t, t, c) |^2 \Big] $$
The two modes of audio generation differ in the conditioning signals used to steer the audio generation process. Both modes of audio generation use a global text prompt:
$$ c_{\text{text}} \in \mathbb{R}^{L \times d_{\text{text}}} $$
where $L$ is the number of text tokens and $d_{\text{text}}$ the text-embedding dimension. This conditioning is global, meaning it is fixed across time.
Stem-conditioned audio generation uses additional time-varying conditioning signals. For Adapt, these are one or more audio stems:
$$ c_{\text{stems}} = \{c^{(s)} \in \mathbb{R}^{T \times D_s}\}, \\[0.3em] \quad s \in \{\text{drums}, \text{bass}, \text{melody}, \text{vocals}, \text{instruments}\} $$
extracted from existing tracks. The rectified flow model is conditioned as:
$$ v_\theta(x_t, t, c_{\text{text}}, c_{\text{stems}}) $$
allowing it to generate one or more new stems aligned with the original track. These generated stems can then be mixed to create an individually adapted version of the original track.
Text-to-music generation corresponds to omitting the stem-conditioning term:
$$ v_\theta(x_t, t, c_{\text{text}}) $$
As of today, Adapt uses only audio as a time-varying conditioning signal, but many other signals — such as melody, rhythm, or dynamics — are possible. Notable models using such inputs include Music ControlNet [3] and MusicGen [4].
On the impact of competing conditioning signals
As already alluded to, scaling conditioning signals beyond a single modality raises novel research questions about the interactions of multiple signals. Problems occur when conditioning signals encode different or incompatible intents.
For example, conditioning signals may compete during generation if the text prompt’s instruction clashes with the musical information in the conditioning audio. Misaligned or competing instructions could force the model to prioritize either the semantic meaning of the text or the composition of the conditioning audio.
We propose a method and apply it to quantify the impact of aligned and conflicting stem conditioning and compare it with text-only audio generation. We define the two cases as follows: conditioning signals are aligned when the text prompt and conditioning audio share the same musical characteristics and style; and they are conflicting when the conditioning audio differs in characteristics and style from the target text prompt.
We hypothesize that conflicting conditioning signals will compete for influence during generation, resulting in lower prompt adherence of the model. Conversely, when conditioning signals are aligned, we expect the model to maintain high prompt adherence, potentially exceeding that of text-only generation.
To validate this hypothesis and gain insights into how conditioning signals influence the model output, we designed and ran an experiment evaluating the effect of different types of conditioning on prompt adherence. Before outlining the experimental setup, we first introduce the state-of-the-art methodology for measuring prompt adherence in music generation models.
Measuring prompt adherence
In music generation, a model’s prompt adherence is measured using CLAP (Contrastive Language-Audio Pretraining) similarity scores [5]. CLAP scores quantify the semantic alignment between (generated) audio and a text prompt by computing the cosine similarity between the embeddings of the audio and the text in a shared embedding space. CLAP is a model that is trained to learn such a shared embedding space using a contrastive loss.
These CLAP scores allow us to determine whether the generated audio aligns with the intended prompt: scores above 0.4 indicate good adherence, while scores below 0.1 suggest little or no alignment [6]. It is important to note that CLAP scores only measure semantic alignment and do not assess musical composition or audio quality. More details about CLAP and its architecture can be found in [5].
Multiple CLAP model variants exist, trained on different datasets such as general audio, music, and speech, each suited to specific tasks. For this experiment, we use the CLAP checkpoint trained on music datasets (music_audioset_epoch_15_esc_90.14.pt) as listed on the official LAION-CLAP GitHub page.
Conditioning signal evaluation setup
To test our hypothesis, we conducted an experiment using crafted prompt-audio pairs that were either aligned or conflicting. Specifically, we created text prompts based on real track metadata and used them to generate audio under three conditioning types: aligned, conflicting, and text-only conditioning. We then computed the CLAP score between each prompt and its generated audio to assess whether the distributions of scores differed across conditioning types.
For the experiment, we selected 51 instrumental tracks across seven genres from Epidemic Sound’s catalog: electronic (8), hip-hop (8), pop (8), classical (7), ambient (7), Latin (7), and rock (6). Track metadata (genre, mood, and style) was used to construct one comma-separated prompts per track, which were naturally aligned with the audio content.
For conflicting conditioning, we paired each generated prompt with an audio file from a different musical genre. Using these aligned and conflicting pairs, we generated new audio. For comparison, we also generated audio using no audio conditioning. This resulted in audio triplets for each prompt, generated using three different conditioning types.
Once the audio was generated, we calculated the CLAP scores between prompts and generated audio. A visualization of the experimental setup is provided below, showing how three audio files per prompt were generated and scored.
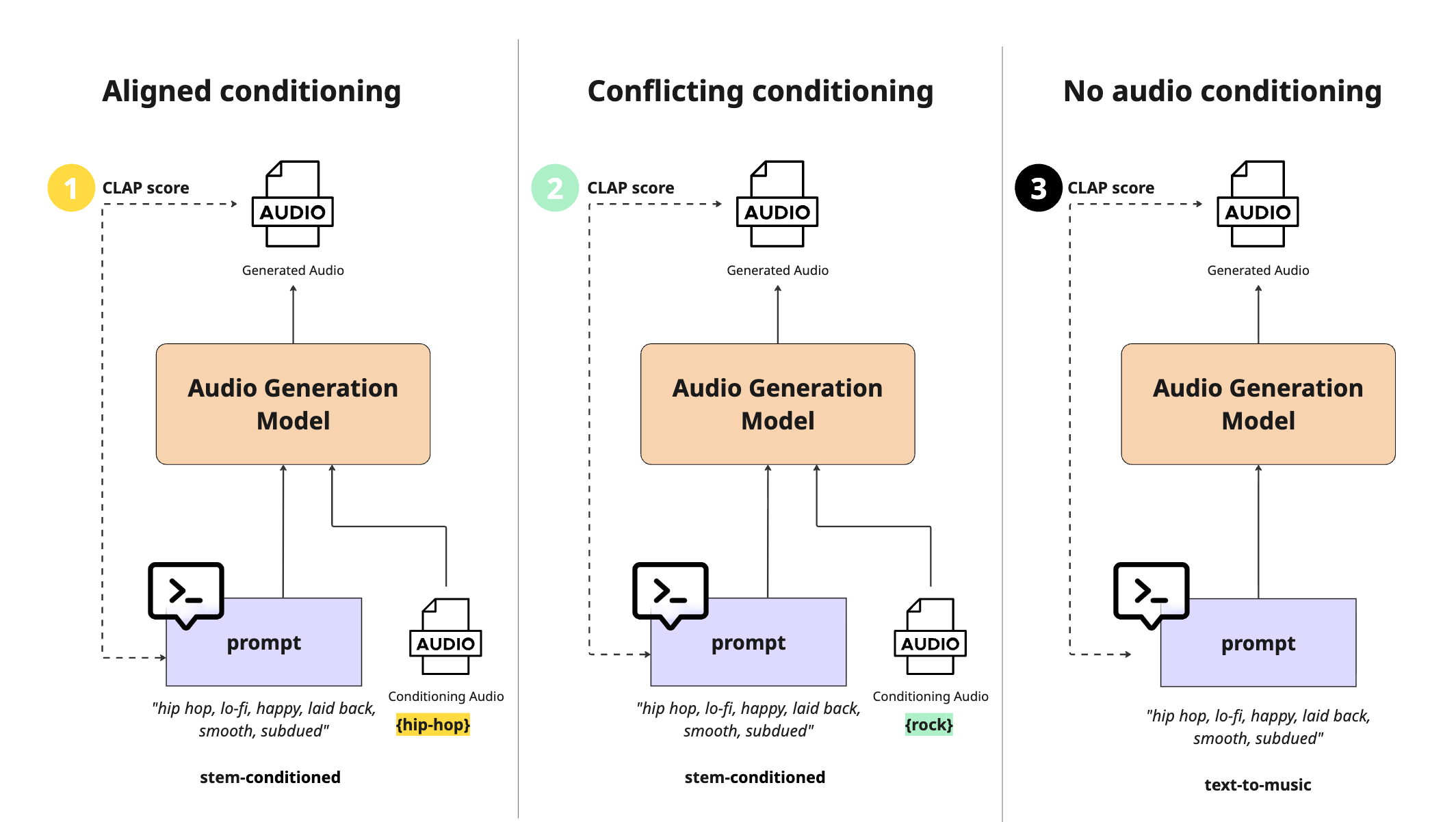
We generated audio using Epidemic Sound’s proprietary latent diffusion model, consisting of a variational autoencoder (VAE) for mapping audio to and from latent space, and a latent diffusion transformer (DiT) for denoising. The transformer was trained using the rectified flow denoising objective. All model hyperparameters were fixed across runs, with a cfg-scale of 1.0 and 8 diffusion steps. To increase robustness, we generated three audio samples per prompt-conditioning pair using different seeds and aggregated the resulting CLAP scores per pair before statistical analysis.
For evaluation, we performed repeated measures ANOVA to test whether the mean CLAP scores differed across conditioning types. The null hypothesis ($H_0$) assumed that audio conditioning has no effect on prompt adherence, meaning the mean of the CLAP score distributions are the same across the three groups (aligned, conflicting, and no conditioning). Inversely the alternative hypothesis ($H_A$) assumes at least one of the means across the three groups is different.
$$ H_0:\ \mu_{\mathrm{CLAPaligned}} = \mu_{\mathrm{CLAPconflicting}} = \mu_{\mathrm{CLAPtext\text{-}only}} $$
$$H_A : \text{At least one } \mu_{\text{CLAP}i} \text{ is different}, \\[0.3em] \quad i \in \{\text{aligned}, \text{conflicting}, \text{text-only}\} $$
Further, we performed paired t-tests to compare the distribution means between each conditioning type.
$$\Delta_{\text{CLAP}_i}^{(j,k)} = \mu_{\text{CLAP}_{i,j}} - \mu_{\text{CLAP}_{i,k}}, \\[0.3em] j, k \in \{\text{aligned}, \text{conflicting}, \text{text-only}\} $$
$$\begin{aligned}H_0 &: \mathbb{E}[\Delta_{\text{CLAP}}^{(j,k)}] = 0 \\[0.5em] H_A &: \mathbb{E}[\Delta_{\text{CLAP}}^{(j,k)}] > 0 \end{aligned}$$
where $i = 1, \dots, N$ indexes text prompts (for each audio triplets), and $\mu_{\text{CLAP}_{i,j}}$ denotes the mean CLAP score for prompt $i$ under conditioning type $j$ and $\Delta_{\text{CLAP}_i}^{(j,k)}$ is the pairwise difference between two conditioning types for the same prompt but different audio.
Impact of signal alignment on prompt adherence
In the following section, we present the results of our experiment. The plot below shows the CLAP scores per conditioning type.
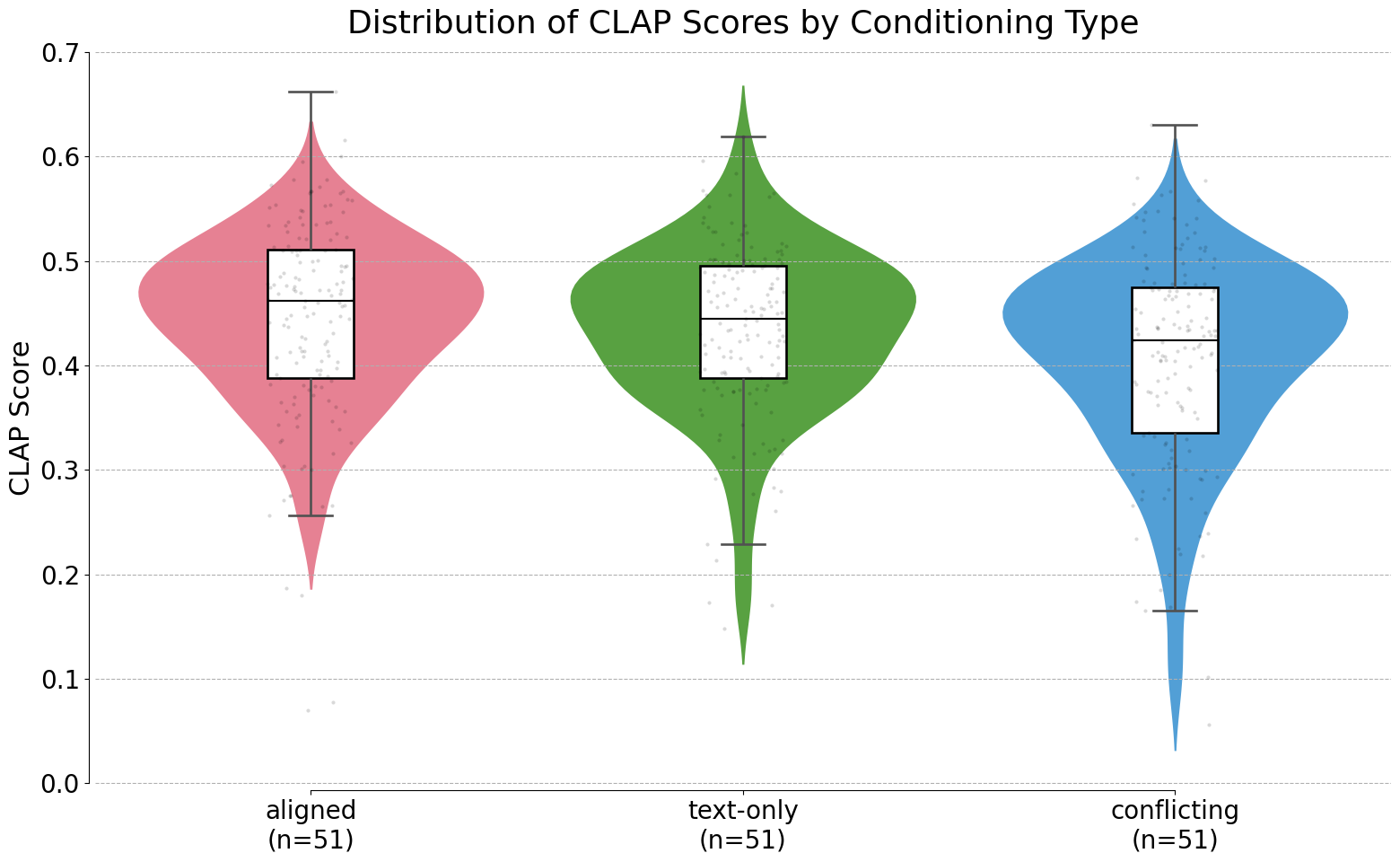
The plot shows that, as expected, audio generated with aligned conditioning signals (red) achieved the highest median CLAP score of around 0.46, followed by text-only conditioned generation (green) with a median of 0.44. Audio conditioned on conflicting signals (blue) had the lowest scores, with a median of 0.42.
Next, we ran a repeated-measures ANOVA to test whether the group means differed significantly. The analysis showed a significant effect of conditioning type (F=7.87, p=0.0007), allowing us to reject the null hypothesis and conclude that CLAP score distributions differ across conditioning types.
To further investigate, we performed one-sided paired t-tests across prompts, with Holm correction for multiple comparisons. The results were as follows:
- Aligned conditioning vs. conflicting conditioning: Significantly higher prompt adherence for aligned stems (p=0.0008)
- Conflicting conditioning vs. text-only: Significantly lower adherence for conflicting stems (p=0.0232)
- Aligned conditioning vs. text-only: No significant difference (p=0.2961)
These results confirm that aligned stems improve prompt adherence, while conflicting stems reduce it, but most interestingly the effect size remains small.
Conclusion
To conclude, our experiments confirm our hypothesis: conflicting conditioning signals slightly reduce prompt adherence, while aligned conditioning signals improve it. Importantly, even when the reduction is statistically significant, it is relatively small, indicating that the model still generates audio that incorporates conflicting stems while following the global text prompt to a satisfactory degree.
These results suggest that users can confidently experiment with adding stems from different styles or genres without losing overall alignment to their text prompts. This enables many creative possibilities for remixing or personalizing tracks while maintaining musical coherence.
Clearly, this experiment only scratches the surface of many interesting research questions. While CLAP scores provide a useful measure of overall audio-text alignment, they do not capture aspects of musical composition, such as quality, complexity, or novelty.
Future work could explore metrics for musical quality, emotional impact, or listener preference. Quantitative metrics are valuable for analysis and statistical evaluation, but they cannot fully capture the richness and human perception of music. Ultimately, listening remains the most meaningful evaluation.
References
[1] - Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. Xingchao Liu, Chengyue Gong, Qiang Liu. ICLR 2023
[2] - Fast Text-to-Audio Generation with Adversarial Post-Training. Zachary Novack, Zach Evans, Zack Zukowski, Josiah Taylor, CJ Carr, Julian Parker, Adnan Al-Sinan, Gian Marco Iodice, Julian McAuley, Taylor Berg-Kirkpatrick, Jordi Pons. 2025
[3] - Music ControlNet: Multiple Time-Varying Controls for Music Generation. Shih-Lun Wu, Chris Donahue, Shinji Watanabe, Nicholas J. Bryan. IEEE ACM Trans. Audio Speech Lang. Process. 2024
[4] - MusicGen: Simple and Controllable Music Generation. Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez. NeurIPS 2023
[5] - CLAP: Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation. Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov. ICASSP 2023
[6] - Fast Timing-Conditioned Latent Audio Diffusion. Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, Jordi Pons. ICML 2024